Compiler Architecture
The Gallium compiler works in a very similar way to the pipeline described in the Crash Course Introduction, albeit with more intermediary steps and lots more complexity.
Driver
The driver in driver.cc strings together the different parts of the compiler, insuring that
they are used at all (or not used), used correctly, and that invariants are enforced between modules.
It handles most of the CLI stuff, the rest of the compiler can only look into gal::flags
in flags.cc to check global options.
Parsing
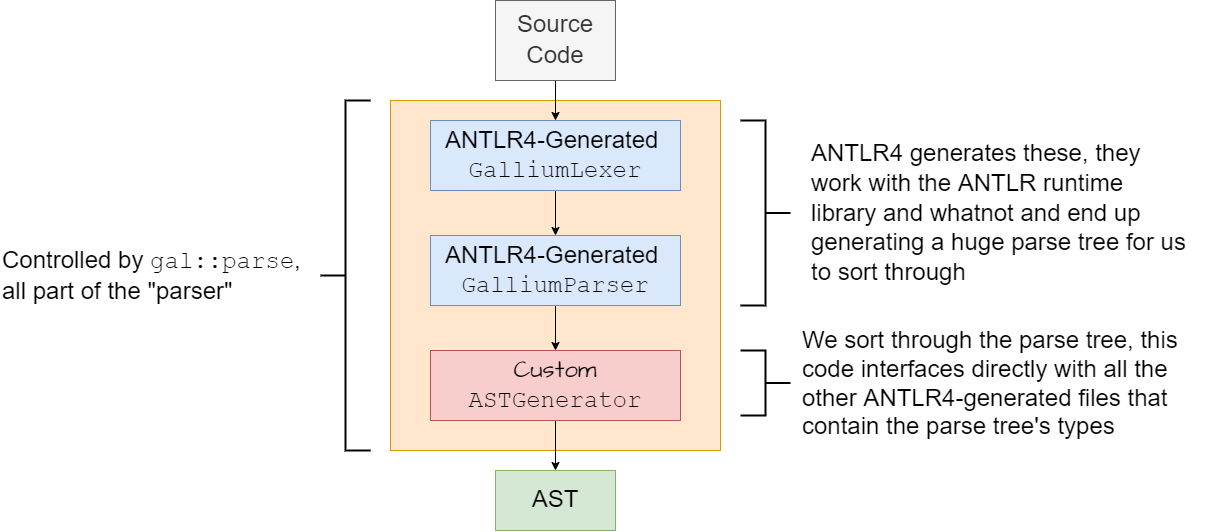
The lexer and parser is handled with ANTLR4. The actual
source code of the parser is split between several files in the compiler/src/syntax
subdirectory.
- Gallium.g4
-
This contains the actual grammar of the parser that ANTLR4 compiles into C++ files during the build phase. These C++ files provide a lexer, parser, and interfaces for using the parse tree that ANTLR parsers emit.
Note that it emits a parse tree and not an AST, the tree still contains all the information that was present in the original source code.
-
- parser.cc / parser.h
-
These files implements the parser interface for the compiler: they provide a
parsefunction that takes in source code and a few options, and it either returns an AST or reports some errors and returns an emptystd::optional.parser.ccimplements ANTLR4’sBaseVisitorinterface for visiting a parse tree, it visits the parse tree node by node and generates an AST piece-by-piece that models the same information.Note that
parser.ccis the only file in the project that directly includes/interacts with the C++ files and headers generated by ANTLR: this is by design, it provides decent isolation and also prevents recompilation of half the project when the grammar is modified.
-
- parse_errors.cc / parse_errors.h
- These files implement ANTLR4’s optional error reporting interface that it will use to report syntax errors if it is unable to parse for whatever reason. It effectively just maps between ANTLR4 diagnostics and the diagnostic interface that the compiler uses internally.
Analysis
The analysis passes are unfortunately very highly coupled, and can’t really be changed by themselves. I would suggest trying to decouple similar passes in your own compiler, as right now a lot of logically “related” tasks are split up between the analysis passes because it was simpler to make it work like that in the moment.
Right now, the type checking “pass” is the entry point for analysis. Once that is invoked, the type checker itself will start running name resolution, symbol table generation and other analyses before it begins to type-check. Some of those analyses are not done before type-checking but are actually done during type-checking in order to resolve possibly ambiguous lookups, because entering/leaving scopes, registering variables, etc. is done by the type checker.
Basically, the TypeChecker class ends up being more of an AnalysisController class masquerading as a type checker pass.
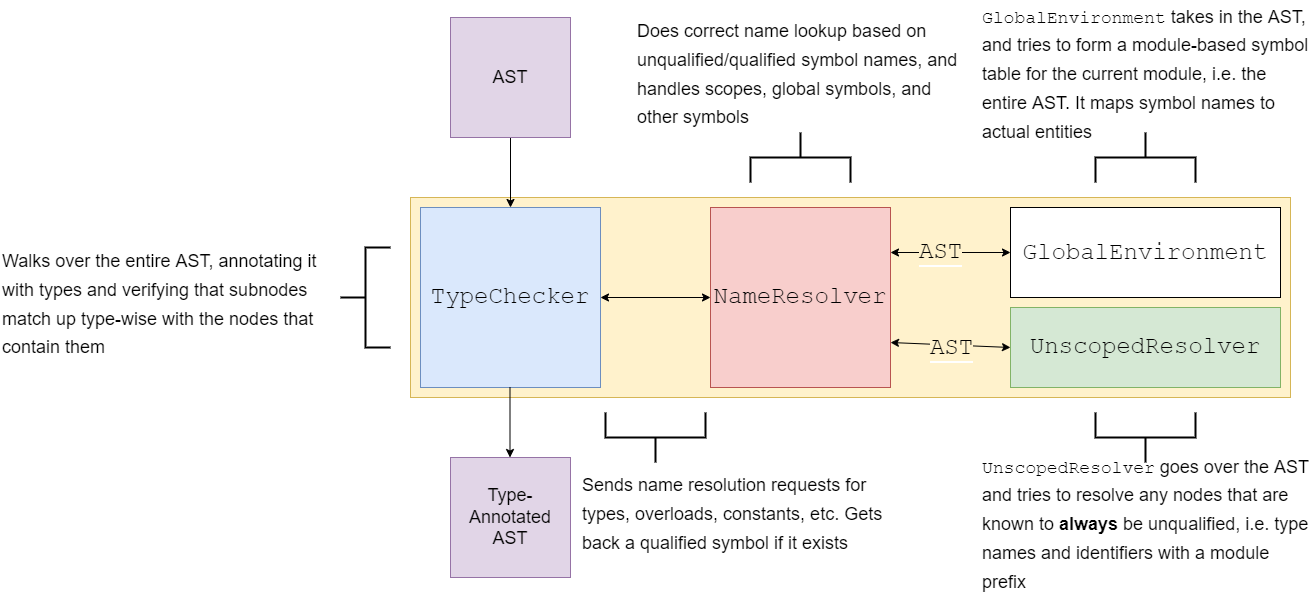
A simplified model looks something like that. Unfortunately all of these pieces are much more complex and entangled internally, and all of them are using internal datastructures to further break down the data.
tl;dr: please don’t do what I did here, it is a pain to actually change anything
Pre-Codegen
Before codegen, name mangling needs to happen. The mangler.cc file contains the mangling API, and an accompanying demangle API for debug purposes.
Mangling further annotates the AST with symbol names, and it must happen before the AST is fed into the code generator.
Code Generation
Code generation is a relatively streamlined pipeline, focused around one main class: CodeGenerator.
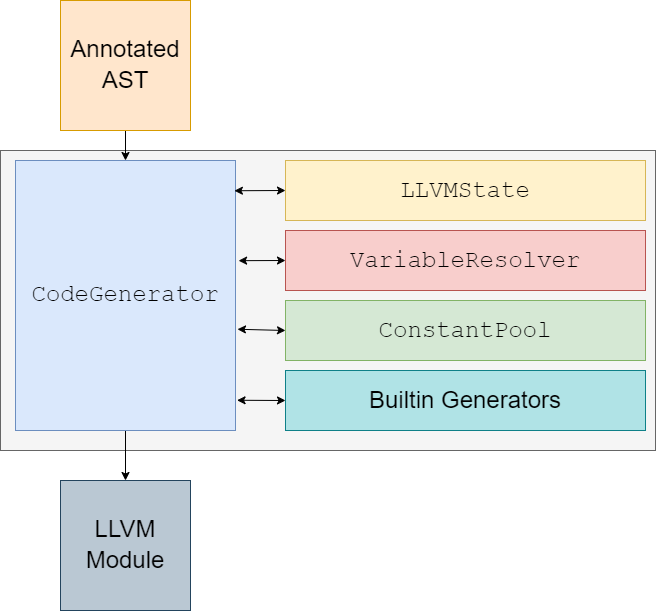
The entire process is guided by the CodeGenerator class. The class walks the annotated AST, and generates
code/orchestrates the other modules as needed. It acts both as the main code generator (since it does the heavy lifting of
generating all the IR for “normal” code), and it properly delegates to the other codegen modules when those tasks are
required. Effectively, it makes decisions for everything codegen-related.
The other classes/modules (collections of functions) in the process are not strictly necessary, but aid in compartmentalization of the codegen process.
core/backend directory
- llvm_state.cc:
LLVMState- Manages LLVM-specific state, e.g.
IRBuilder<>,LLVMContext,Module,TargetMachine,DataLayout, etc. It doesn’t do much codegen on its own, besides setting up the module’s target information.
- Manages LLVM-specific state, e.g.
- variable_resolver.cc:
VariableResolver- Handles managing stack-allocated variables, including name lookup, loading, etc. It handles codegen
to correctly access variables, and it also is informed whenever the variables are destroyed (and
can tell LLVM where necessary). It’s effectively the codegen version of
NameResolverfor local variables (since it’s unambiguous if a variable is local or global at this point).
- Handles managing stack-allocated variables, including name lookup, loading, etc. It handles codegen
to correctly access variables, and it also is informed whenever the variables are destroyed (and
can tell LLVM where necessary). It’s effectively the codegen version of
- constant_pool.cc:
ConstantPool- Handles global constants, types, other global data outside of functions. Performs loads/codegen as
needed to access global variables and other global data. It also handles creating constants, and
generating correct code to evaluate constants (the compiler term is “constant folding”) at the IR level,
since constant expressions in LLVM’s world are handled in a very different way than standard IR is handled.
Note that this module does not do much constant folding on its own: a lot is handled directly by the
llvm::IRBuilder<>as instructions are emitted. This class only handles creating constant values for initializing globals and other module-scoped data (e.g it handles string literals,constvalues, things like that).
- Handles global constants, types, other global data outside of functions. Performs loads/codegen as
needed to access global variables and other global data. It also handles creating constants, and
generating correct code to evaluate constants (the compiler term is “constant folding”) at the IR level,
since constant expressions in LLVM’s world are handled in a very different way than standard IR is handled.
Note that this module does not do much constant folding on its own: a lot is handled directly by the
- builtins.cc: Builtin Generators
-
While this isn’t a class, its a small codegen module that handles generating code for builtins, and enables actually calling them (since the implementation of them is effectively magic). Whenever the
CodeGeneratorencounters a call to an intrinsic, it will tell this module and let this module handle generating the “call.”Some builtins are implemented as weak symbols in the IR itself, some are runtime library features, some are implemented through special in-line IR generation, etc. It’s the job of this module to keep up with that.
-
After the CodeGenerator class has finished operating on a module, that module is guaranteed
to be correct, but not optimized. Optimization (or lack thereof) is handled later.
Weird Parts of Codegen
The code generator uses this StoredValue type everywhere to help deal with values that need
to either be in memory or in registers for IR correctness, as it keeps track of where a value in
the IR is actually located.
This helps to deal with oddities that I unfortunately did not model the AST to deal with, such as
the difference between arr[10] := 5 and arr[10] + 5. arr[10] creates a pointer by default
for correctness’ sake, and then codegen that needs operands in a reg will just use codegen_promoting.
codegen_promoting will use the location in the StoredValue to know whether it needs to insert a magical
load in there or not.
Optimization and Emitting
Optimization and emitting are both tasks that are separate from the IR generation.
Both are completely optional in fact, as the LLVM module can just be used directly if the driver sees fit.